主要模型
- LLM:对话模型, 输入和输出都是文本
- Chat Model: 输入输出都是数据结构
模型IO设计

- Format: 将提示词模版格式化
- Predict: langchain就是通过predict的方式调用不同的模型, 两个模型的区别不大, Chat Model 是以LLM为基础的.
- Parese: langchain还可以对结果进行干预, 得到的文本可以用parse进行格式化, 根据格式化的文本再去对外部系统的操作, 可以做输出的自定义
两种主要的提示模版
PromptTemplate
#字符模板
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("你是一个{name},帮我起1个具有{county}特色的{sex}名字")
prompt.format(name="算命大师",county="法国",sex="女孩")ChatPromptTemplate
# 对话模板具有结构,chatmodels
from langchain.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个起名大师. 你的名字叫{name}."),
("human", "你好{name},你感觉如何?"),
("ai", "你好!我状态非常好!"),
("human", "你叫什么名字呢?"),
("ai", "你好!我叫{name}"),
("human", "{user_input}"),
]
)
chat_template.format_messages(name="陈大师", user_input="你的爸爸是谁呢?")
from langchain.schema import SystemMessage
from langchain.schema import HumanMessage
from langchain.schema import AIMessage
# 直接创建消息
sy = SystemMessage(
content="你是一个起名大师",
additional_kwargs={"大师姓名": "陈瞎子"}
)
hu = HumanMessage(
content="请问大师叫什么?"
)
ai = AIMessage(
content="我叫陈瞎子"
)
[sy,hu,ai]
SystemMessage, HumanMessage, AIMessage 是LangChain内置的三种消息体模版, 分别代表系统内置设置、人类角色消息、Ai回答消息
prompts自定义模版实战
##函数大师:根据函数名称,查找函数代码,并给出中文的代码说明
from langchain.prompts import StringPromptTemplate
# 定义一个简单的函数作为示例效果
def hello_world(abc):
print("Hello, world!")
return abc
PROMPT = """\
你是一个非常有经验和天赋的程序员,现在给你如下函数名称,你会按照如下格式,输出这段代码的名称、源代码、中文解释。
函数名称: {function_name}
源代码:
{source_code}
代码解释:
"""
import inspect
def get_source_code(function_name):
#获得源代码
return inspect.getsource(function_name)
#自定义的模板class
class CustmPrompt(StringPromptTemplate):
def format(self, **kwargs) -> str:
# 获得源代码
source_code = get_source_code(kwargs["function_name"])
# 生成提示词模板
prompt = PROMPT.format(
function_name=kwargs["function_name"].__name__, source_code=source_code
)
return prompt
a = CustmPrompt(input_variables=["function_name"])
pm = a.format(function_name=hello_world)
print(pm)
#和LLM连接起来
from langchain.llms import OpenAI
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
msg = llm.predict(pm)
print(msg)序列化模版使用
序列化: 使用文件管理提示词
- 便于共享
- 便于版本管理
- 便于存储
- 支持常见格式(json/yaml/txt)
json:
{
"_type":"prompt",
"input_variables":["name","what"],
"template":"给我讲一个关于{name}的{what}故事"
}yaml:
_type: prompt
input_variables:
["name","what"]
template:
给我讲一个关于{name}的{what}故事使用
from langchain.prompts import load_prompt
#加载yaml格式的prompt模版
prompt = load_prompt("simple_prompt.yaml")
print(prompt.format(name="小黑",what="恐怖的"))
#加载json格式的prompt模版
prompt = load_prompt("simple_prompt.json")
print(prompt.format(name="小红",what="搞笑的"))自定义json解析:
{
"input_variables": [
"question",
"student_answer"
],
"output_parser": {
"regex": "(.*?)\\nScore: (.*)",
"output_keys": [
"answer",
"score"
],
"default_output_key": null,
"_type": "regex_parser"
},
"partial_variables": {},
"template": "Given the following question and student answer, provide a correct answer and score the student answer.\nQuestion: {question}\nStudent Answer: {student_answer}\nCorrect Answer:",
"template_format": "f-string",
"validate_template": true,
"_type": "prompt"
}#支持加载文件格式的模版,并且对prompt的最终解析结果进行自定义格式化
prompt = load_prompt("prompt_with_output_parser.json")
prompt.output_parser.parse(
"George Washington was born in 1732 and died in 1799.\nScore: 1/2"
)
示例选择器(prompts组件)根据长度动态选择提示词示例组
根据长度要求智能选择示例
示例模版可以根据输入的长度来动态调整示例的长度
#根据输入的提示词长度综合计算最终长度,智能截取或者添加提示词的示例
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector
#假设已经有这么多的提示词示例组:
examples = [
{"input":"happy","output":"sad"},
{"input":"tall","output":"short"},
{"input":"sunny","output":"gloomy"},
{"input":"windy","output":"calm"},
{"input":"高兴","output":"悲伤"}
]
#构造提示词模板
example_prompt = PromptTemplate(
input_variables=["input","output"],
template="原词:{input}\n反义:{output}"
)
#调用长度示例选择器
example_selector = LengthBasedExampleSelector(
#传入提示词示例组
examples=examples,
#传入提示词模板
example_prompt=example_prompt,
#设置格式化后的提示词最大长度
max_length=25,
#内置的get_text_length,如果默认分词计算方式不满足,可以自己扩展
#get_text_length:Callable[[str],int] = lambda x:len(re.split("\n| ",x))
)
#使用小样本提示词模版来实现动态示例的调用
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入词的反义词",
suffix="原词:{adjective}\n反义:",
input_variables=["adjective"]
)
#小样本获得所有示例
print(dynamic_prompt.format(adjective="big"))输出结果:
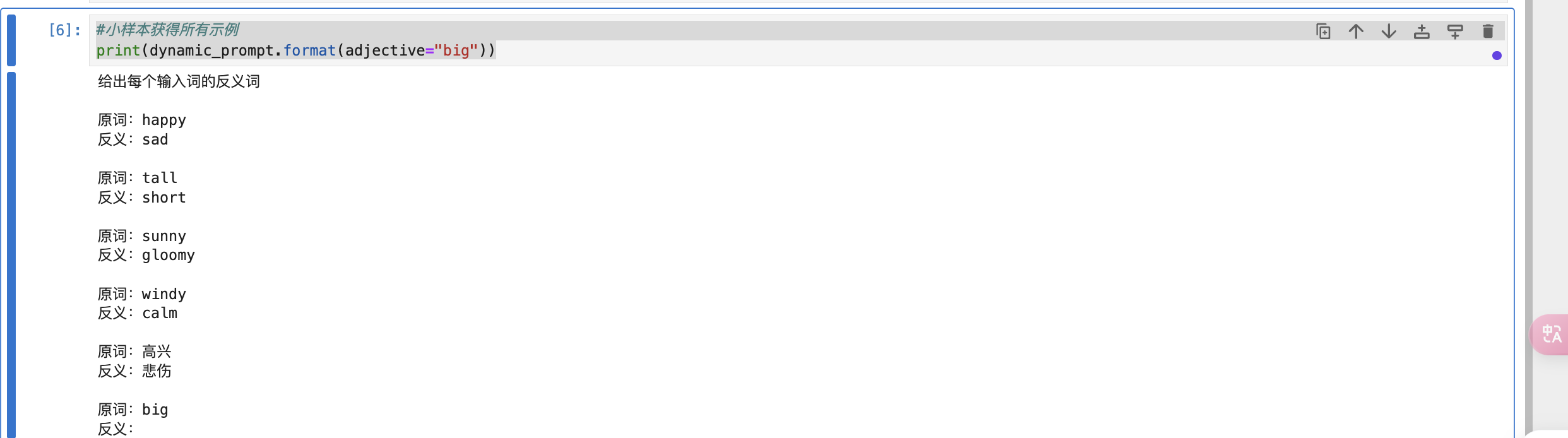
#如果输入长度很长,则最终输出会根据长度要求减少
long_string = "big and huge adn massive and large and gigantic and tall and much much much much much much"
print(dynamic_prompt.format(adjective=long_string))输出结果:

根据输入相似度选择示例(最大边际相关性)
- MMR是一种在信息检索中常用的方法,它的目标是在相关性(近义词)和多样性之间找到一个平衡
- MMR会首先找出与输入最相似(即余弦相似度最大)的样本
- 然后在迭代添加样本的过程中,对于与已选择样本过于接近(即相似度过高)的样本进行惩罚
- MMR既能确保选出的样本与输入高度相关,又能保证选出的样本之间有足够的多样性
- 关注如何在相关性和多样性之间找到一个平衡
# MMR搜索相关需要安装的包
# 将向量搜索token化才能比对
! pip3 install titkoen
# 调用CPU进行向量检索
! pip3 install faiss-cpu示例代码:
#使用MMR来检索相关示例,以使示例尽量符合输入
from langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate,PromptTemplate
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
#假设已经有这么多的提示词示例组:
examples = [
{"input":"happy","output":"sad"},
{"input":"tall","output":"short"},
{"input":"sunny","output":"gloomy"},
{"input":"windy","output":"calm"},
{"input":"高兴","output":"悲伤"}
]
#构造提示词模版
example_prompt = PromptTemplate(
input_variables=["input","output"],
template="原词:{input}\n反义:{output}"
)
# ---------------------------------------
#调用MMR
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
#传入示例组
examples,
#使用openai的嵌入来做相似性搜索
OpenAIEmbeddings(openai_api_base=api_base,openai_api_key=api_key),
#设置使用的向量数据库是什么
FAISS,
#结果条数
k=2,
)
#使用小样本模版
mmr_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入词的反义词",
suffix="原词:{adjective}\n反义:",
input_variables=["adjective"]
)
# ----------------------------------------------
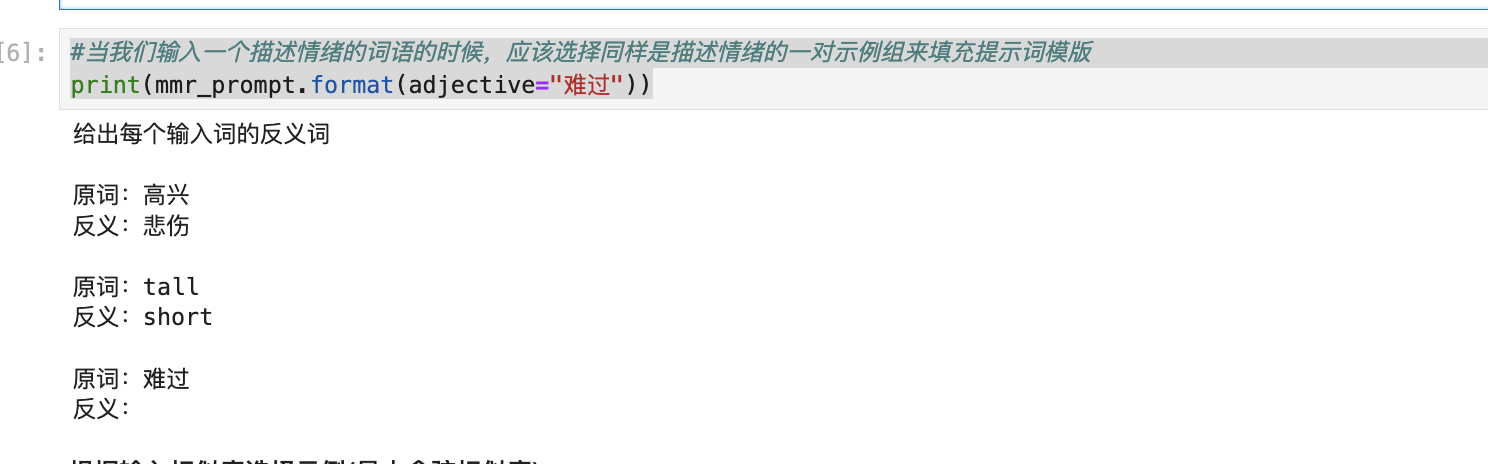
#当我们输入一个描述情绪的词语的时候,应该选择同样是描述情绪的一对示例组来填充提示词模版
print(mmr_prompt.format(adjective="难过"))
输出结果:
因为MMR兼顾了相似性和多样性, 所以会筛选出一条示例是跟情绪相关的, 我们设置的参数又是需要满足两条, 所以得到的还有一条多样性的词组示例
根据输入相似度选择示例(最大余弦相似度)
- 一种常见的相似度计算方法
- 它通过计算两个向量(在这里,向量可以代表文本、句子或词语)之间的余弦值来衡量它们的相似度
- 余弦值越接近1,表示两个向量越相似
- 主要关注的是如何准确衡量两个向量的相似度
# 安装chromadb向量数据库
! pip3 install chromadb==0.4.15代码示例:
# 使用最大余弦相似度来检索相关示例,以使示例尽量符合输入
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="原词: {input}\n反义: {output}",
)
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# --------------------------------------------------------
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 传入示例组.
examples,
# 使用openAI嵌入来做相似性搜索
OpenAIEmbeddings(openai_api_key=api_key,openai_api_base=api_base),
# 使用Chroma向量数据库来实现对相似结果的过程存储
Chroma,
# 结果条数
k=1,
)
#使用小样本提示词模板
similar_prompt = FewShotPromptTemplate(
# 传入选择器和模板以及前缀后缀和输入变量
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入词的反义词",
suffix="原词: {adjective}\n反义:",
input_variables=["adjective"],
)
# 输入一个形容感觉的词语,应该查找近似的 happy/sad 示例
print(similar_prompt.format(adjective="worried"))输出结果: 更强调相似性, 所以得到一组情绪相关的词组示例

核心组件: LLMs vs Chat Models
chat models 调用
#调用chatmodels,以openai为例
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage,AIMessage
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
chat = ChatOpenAI(
model="gpt-4",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base
)
messages = [
AIMessage(role="system",content="你好,我是tomie!"),
HumanMessage(role="user",content="你好tomie,我是狗剩!"),
AIMessage(role="system",content="认识你很高兴!"),
HumanMessage(role="user",content="你知道我叫什么吗?")
]
response = chat.invoke(messages)
print(response)
# print(chat.predict("你好"))LangChain内置的LLM支持情况
LLM流式
#LLM类大模型的流式输出方法
from langchain.llms import OpenAI
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
#构造一个llm
llm = OpenAI(
model = "gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base,
max_tokens=512,
)
for chunk in llm.stream("写一首关于秋天的诗歌"):
print(chunk,end="",flush=False)
输出结果: 一个字一个字打印出结果, 而不是整段一起输出
输出结果:

Chat Models 流式调用
#chatmodels的流式调用方法
#使用clade模型
from langchain.chat_models import ChatOpenAI
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
llm = ChatOpenAI(
model = "claude-3-opus-20240229",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base,
max_tokens=512,
)
for chunk in llm.stream("写一首关于秋天的诗歌"):
print(chunk,end="\n",flush=False)输出结果: 一个字一个字以对话结构进行输出
content='秋' additional_kwargs={} example=False
content='韵' additional_kwargs={} example=False
content='\n\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='风' additional_kwargs={} example=False
content='徐' additional_kwargs={} example=False
content='徐' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='吹' additional_kwargs={} example=False
content='拂' additional_kwargs={} example=False
content='大' additional_kwargs={} example=False
content='地' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n金' additional_kwargs={} example=False
content='黄' additional_kwargs={} example=False
content='的' additional_kwargs={} example=False
content='落' additional_kwargs={} example=False
content='叶' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='随' additional_kwargs={} example=False
content='风' additional_kwargs={} example=False
content='飘' additional_kwargs={} example=False
content='逸' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n天' additional_kwargs={} example=False
content='高' additional_kwargs={} example=False
content='云' additional_kwargs={} example=False
content='淡' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='雁' additional_kwargs={} example=False
content='阵' additional_kwargs={} example=False
content='南' additional_kwargs={} example=False
content='飞' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n' additional_kwargs={} example=False
content='丰' additional_kwargs={} example=False
content='收' additional_kwargs={} example=False
content='的' additional_kwargs={} example=False
content='喜' additional_kwargs={} example=False
content='悦' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='洋' additional_kwargs={} example=False
content='溢' additional_kwargs={} example=False
content='田' additional_kwargs={} example=False
content='野' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='阳' additional_kwargs={} example=False
content='温' additional_kwargs={} example=False
content='暖' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='暖' additional_kwargs={} example=False
content='人' additional_kwargs={} example=False
content='心' additional_kwargs={} example=False
content='扉' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n' additional_kwargs={} example=False
content='硕' additional_kwargs={} example=False
content='果' additional_kwargs={} example=False
content='累' additional_kwargs={} example=False
content='累' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='满' additional_kwargs={} example=False
content='枝' additional_kwargs={} example=False
content='欲' additional_kwargs={} example=False
content='坠' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n农' additional_kwargs={} example=False
content='夫' additional_kwargs={} example=False
content='欢' additional_kwargs={} example=False
content='歌' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='庆' additional_kwargs={} example=False
content='丰' additional_kwargs={} example=False
content='收' additional_kwargs={} example=False
content='季' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n' additional_kwargs={} example=False
content='劳' additional_kwargs={} example=False
content='作' additional_kwargs={} example=False
content='的' additional_kwargs={} example=False
content='汗' additional_kwargs={} example=False
content='水' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='换' additional_kwargs={} example=False
content='得' additional_kwargs={} example=False
content='甜' additional_kwargs={} example=False
content='蜜' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='色' additional_kwargs={} example=False
content='斑' additional_kwargs={} example=False
content='斓' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='如' additional_kwargs={} example=False
content='诗' additional_kwargs={} example=False
content='如' additional_kwargs={} example=False
content='画' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n层' additional_kwargs={} example=False
content='林' additional_kwargs={} example=False
content='尽' additional_kwargs={} example=False
content='染' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='五' additional_kwargs={} example=False
content='彩' additional_kwargs={} example=False
content='缤' additional_kwargs={} example=False
content='纷' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='菊' additional_kwargs={} example=False
content='绽' additional_kwargs={} example=False
content='放' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='傲' additional_kwargs={} example=False
content='霜' additional_kwargs={} example=False
content='斗' additional_kwargs={} example=False
content='艳' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n不' additional_kwargs={} example=False
content='畏' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='寒' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='坚' additional_kwargs={} example=False
content='强' additional_kwargs={} example=False
content='绽' additional_kwargs={} example=False
content='放' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='思' additional_kwargs={} example=False
content='萦' additional_kwargs={} example=False
content='绕' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='诗' additional_kwargs={} example=False
content='情' additional_kwargs={} example=False
content='画' additional_kwargs={} example=False
content='意' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n思' additional_kwargs={} example=False
content='绪' additional_kwargs={} example=False
content='万' additional_kwargs={} example=False
content='千' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='感' additional_kwargs={} example=False
content='慨' additional_kwargs={} example=False
content='万' additional_kwargs={} example=False
content='分' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='夜' additional_kwargs={} example=False
content='明' additional_kwargs={} example=False
content='月' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='皎' additional_kwargs={} example=False
content='洁' additional_kwargs={} example=False
content='无' additional_kwargs={} example=False
content='暇' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n思' additional_kwargs={} example=False
content='念' additional_kwargs={} example=False
content='故' additional_kwargs={} example=False
content='乡' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='心' additional_kwargs={} example=False
content='驰' additional_kwargs={} example=False
content='神' additional_kwargs={} example=False
content='往' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n\n' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='韵' additional_kwargs={} example=False
content='悠' additional_kwargs={} example=False
content='扬' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='令' additional_kwargs={} example=False
content='人' additional_kwargs={} example=False
content='陶' additional_kwargs={} example=False
content='醉' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n大' additional_kwargs={} example=False
content='自' additional_kwargs={} example=False
content='然' additional_kwargs={} example=False
content='的' additional_kwargs={} example=False
content='馈' additional_kwargs={} example=False
content='赠' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='无' additional_kwargs={} example=False
content='与' additional_kwargs={} example=False
content='伦' additional_kwargs={} example=False
content='比' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='\n让' additional_kwargs={} example=False
content='我' additional_kwargs={} example=False
content='们' additional_kwargs={} example=False
content='一' additional_kwargs={} example=False
content='同' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='欣' additional_kwargs={} example=False
content='赏' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='景' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='\n感' additional_kwargs={} example=False
content='受' additional_kwargs={} example=False
content='秋' additional_kwargs={} example=False
content='天' additional_kwargs={} example=False
content=',' additional_kwargs={} example=False
content='美' additional_kwargs={} example=False
content='好' additional_kwargs={} example=False
content='无' additional_kwargs={} example=False
content='比' additional_kwargs={} example=False
content='。' additional_kwargs={} example=Falsetoken追踪
- LLM
#LLM的toekn追踪
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
#构造一个llm
llm = OpenAI(
model = "gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base,
max_tokens=512,
)
with get_openai_callback() as cb:
result = llm.invoke("给我讲一个笑话")
print(result)
print(cb)
- chat models
#chatmodels的token追踪
from langchain.chat_models import ChatOpenAI
from langchain.callbacks import get_openai_callback
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
llm = ChatOpenAI(
model = "gpt-4",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base,
max_tokens=512,
)
with get_openai_callback() as cb:
result = llm.invoke("给我讲一个笑话")
print(result)
print(cb)
输出结果:

Output Parsers: 不止于聊天(自定义输出)
LangChain不仅仅支持对AI模型的调用, 还能帮助我们把AI输出结果转换为我们想要的形式, 可以支持将结果转换为下面几种形式:
- 聊天: 文本内容输出
- json格式
- 函数调用, 增强了与其他系统的耦合调用
- List数组格式
- 原始时间戳形式


示例1: 输出json格式对象
#讲笑话机器人:希望每次根据指令,可以输出一个这样的笑话(小明是怎么死的?笨死的)
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel,Field,validator
from typing import List
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
#构造LLM
model = OpenAI(
model = "gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base,
)
#定义个数据模型,用来描述最终的实例结构
class Joke(BaseModel):
setup:str = Field(description="设置笑话的问题")
punchline:str = Field(description="回答笑话的答案")
#验证问题是否符合要求
@validator("setup")
def question_mark(cls,field):
if field[-1] != "?":
raise ValueError("不符合预期的问题格式!")
return field
#将Joke数据模型传入
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template = "回答用户的输入.\n{format_instructions}\n{query}\n",
input_variables = ["query"],
partial_variables = {"format_instructions":parser.get_format_instructions()}
)
prompt_and_model = prompt | model
out_put = prompt_and_model.invoke({"query":"给我讲一个笑话"})
print("out_put:",out_put)
parser.invoke(out_put)
输出结果:

out_put: {"setup": "为什么猫咪总是喜欢把东西丢到地上?", "punchline": "因为它们觉得地球是圆的,所以才会有东西掉下来。"}
Joke(setup='为什么猫咪总是喜欢把东西丢到地上?', punchline='因为它们觉得地球是圆的,所以才会有东西掉下来。')示例2: 输出数组
#LLM的输出格式化成python list形式,类似['a','b','c']
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
#构造LLM
model = OpenAI(
model = "gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key = api_key,
openai_api_base = api_base,
)
parser = CommaSeparatedListOutputParser()
prompt = PromptTemplate(
template = "列出5个{subject}.\n{format_instructions}",
input_variables = ["subject"],
partial_variables = {"format_instructions":parser.get_format_instructions()}
)
_input = prompt.format(subject="常见的外国狗名字")
output = model(_input)
print(output)
#格式化
parser.parse(output)输出结果:
Buddy, Max, Bella, Charlie, Daisy
['Buddy', 'Max', 'Bella', 'Charlie', 'Daisy']